1. Réduction en clusters
Ce projet a été réalisé en Python.
Partant des dimensions calculées pour un ensemble d'individus, qui ont passé un test, des clusters sont générés en regard d'un certain nombre de
critères. Chaque cluster représente une classe définie par le centre de masse du cluster avec sa déviation standard.
Par la suite, individu nouvellement testé est comparé avec chaque classe et une liste de probqbilités d'affinité avec chaque classe est générée.
Cette liste permet alors de calculer tout un panorama de caractéristiques, à condition que chaque classe soit bien caractérisée.
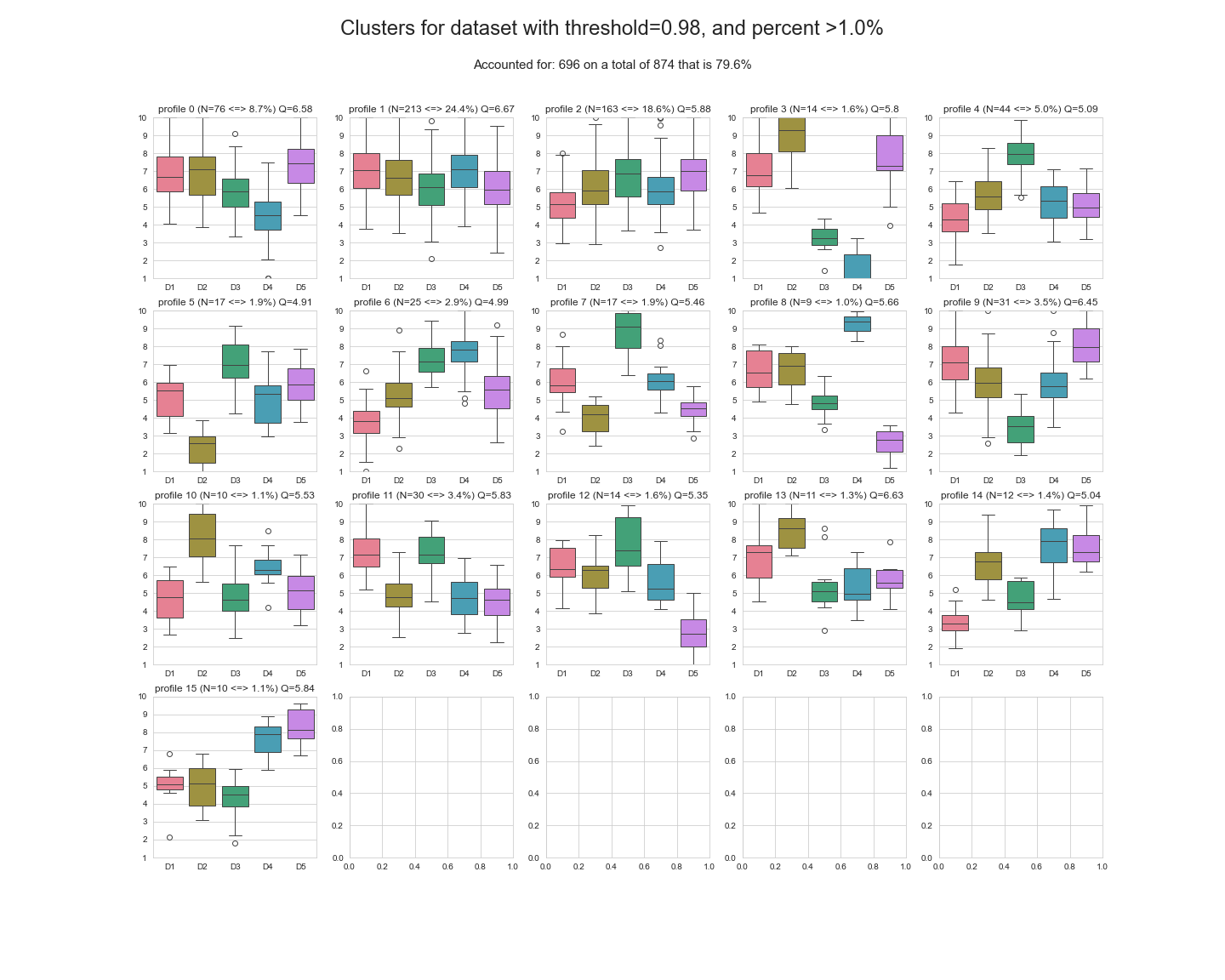
L'image suivante montre le résultat du clustering: un ensemble des regroupement les plus fréquents.
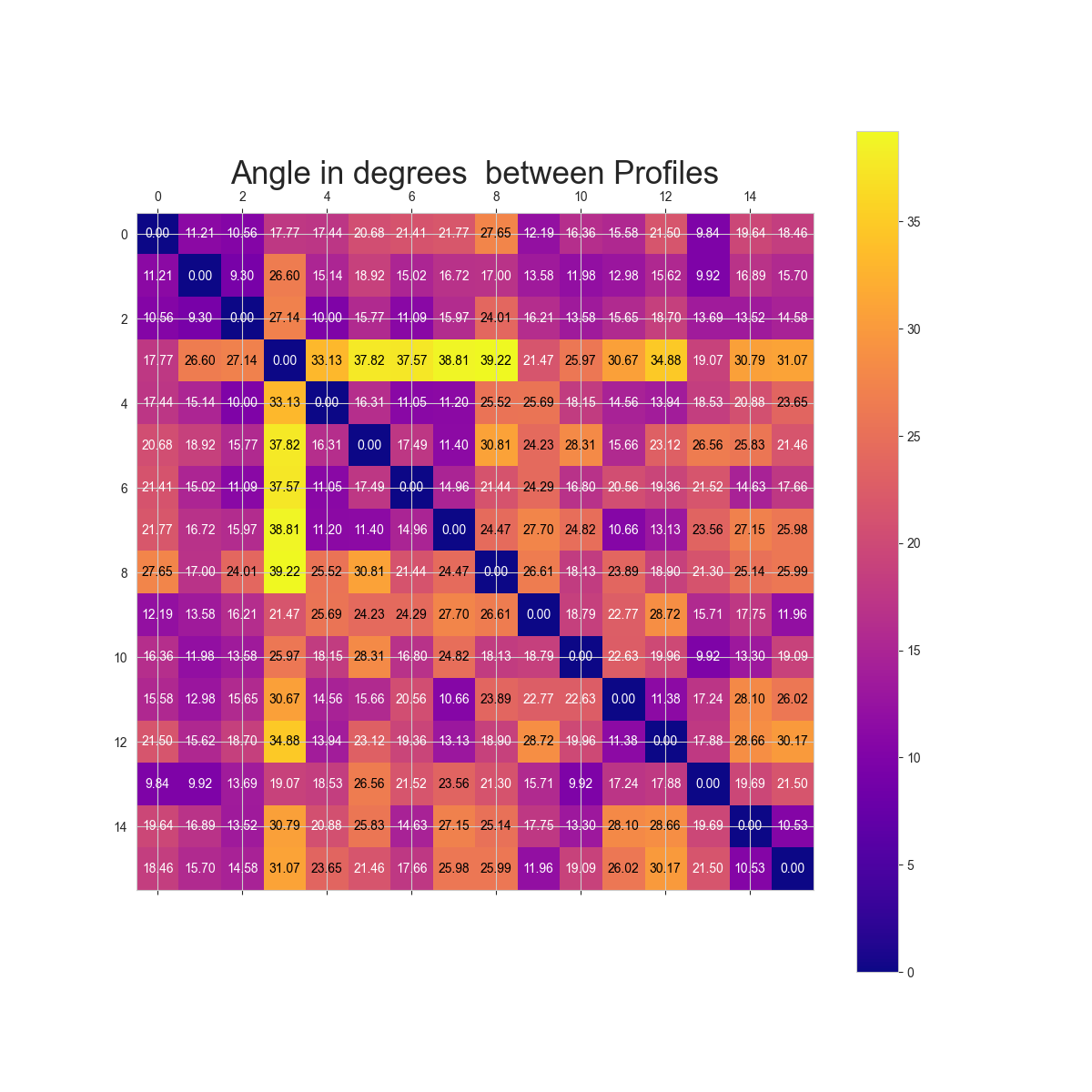
L'image suivante montre la séparation des différents groupes.
2. Identification du profile
Une fois que les profils sont définis, il devient possible de comparer un individu aux différents profils afin d'en déduire le profil dominant de l'individu.
On peut alors appliquer le traitement adéquat en s'appuyant sur ce profil.
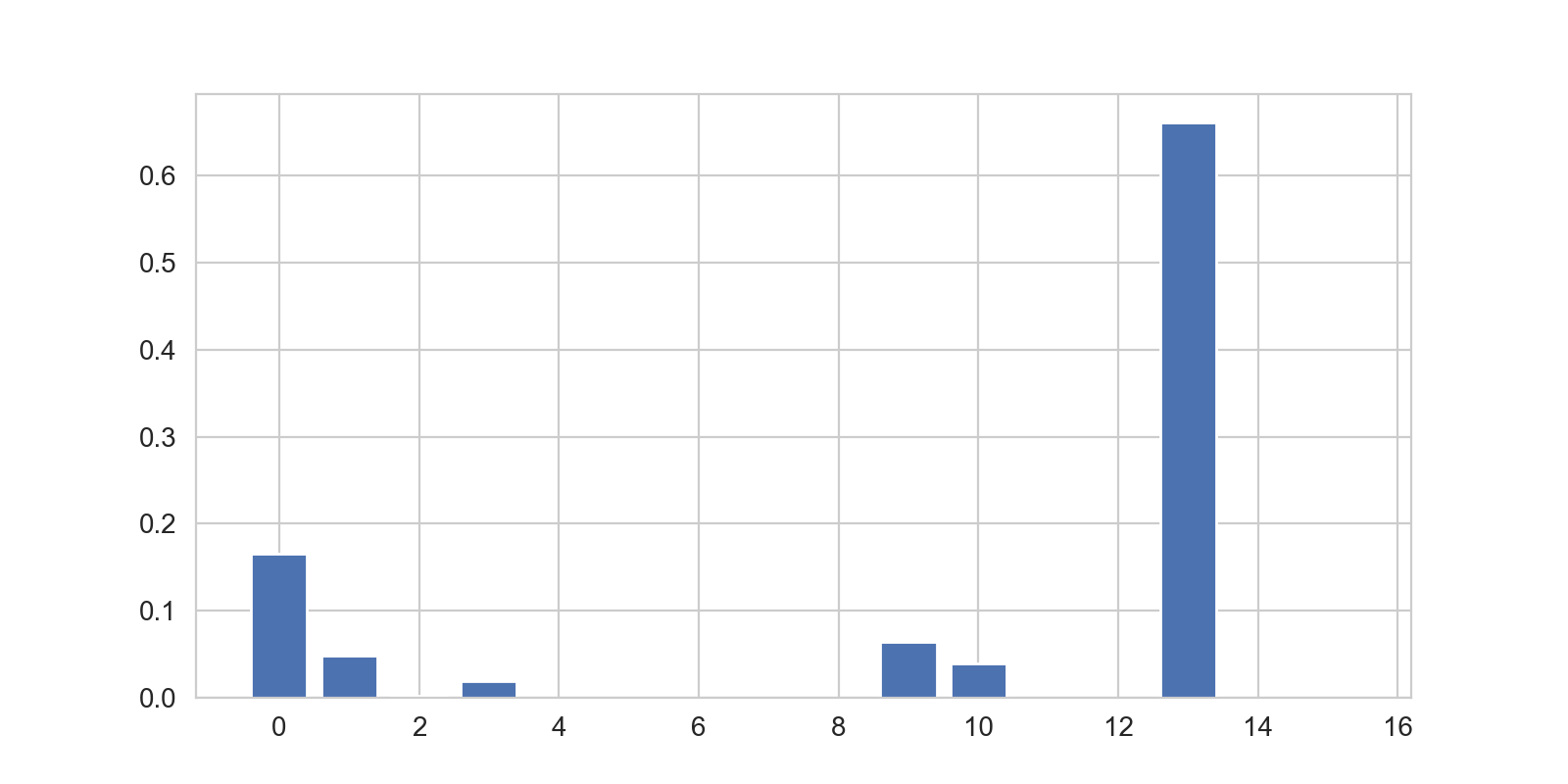
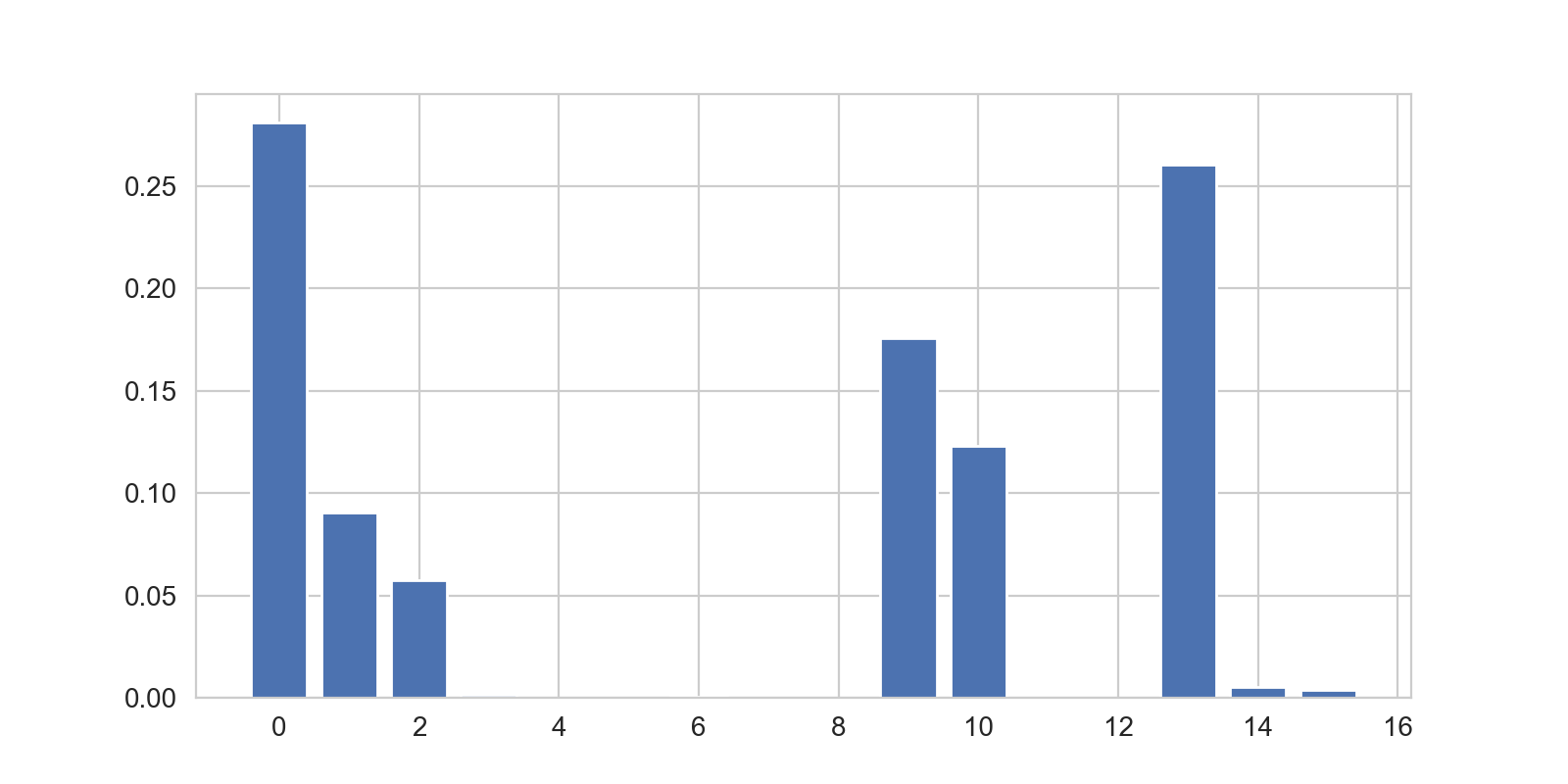
Les images suivantes montrent les comparaisons de deux individus avec les différents profils. Les hauteurs des barres sont d'autant plus élevées que le profil
correspond à l'individu. Il n'est pas rare qu'un individu corresponde à plus d'un profils (certains profils sont assez proches).
In the pictures below we show two different profiles, for which two different kind of actions will be provided.
Concernant les deux individus ci-dessous, deux types d'actions différents seront appliqués.